Метод обратного распространения ошибки — метод обучения многослойного перцептрона. Впервые метод был описан в 1974 г. Полем Дж. Вербосом[1], а также независимо и одновременно А. И. Галушкиным[2]. Далее существенно развит в 1986 г. Дэвидом И. Румельхартом, Дж. Е. Хинтоном и Рональдом Дж. Вильямсом[3] и независимо и одновременно С. И. Барцевым и В. А. Охониным (Красноярская группа)[4]. Это итеративный градиентный алгоритм, который используется с целью минимизации ошибки работы многослойного перцептрона и получения желаемого выхода.
Основная идея этого метода состоит в распространении сигналов ошибки от выходов сети к её входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы. Барцев и Охонин предложили сразу общий метод («принцип двойственности»), приложимый к более широкому классу систем, включая системы с запаздыванием, распределённые системы, и т. п.[5]
Для возможноcти применения метода обратного распространения ошибки передаточная функция нейронов должна быть дифференцируема.
Cигмоидальные функции активации[]
Наиболее часто в качестве функций активации используются следующие виды сигмоид:
Функция Ферми (экспоненциальная сигмоида):

Рациональная сигмоида:

Гиперболический тангенс:

где s — выход сумматора нейрона, — произвольная константа.

Менее всего, сравнительно с другими сигмоидами, процессорного времени требует расчет рациональной сигмоиды. Для вычисления гиперболического тангенса требуется больше всего тактов работы процессора. Если же сравнивать с пороговыми функциями активациями, то сигмоиды расчитываются очень медленно. Если после суммирования в пороговой функции сразу можно начинать сравнение с определенной величиной (порогом), то в случае сигмоидальной функции активации — нужно расчитать сигмоид (затратить время в лучшем случае на три операции: взятие модуля, сложение и деление), и только потом сравнивать с пороговой величиной (например, нулем). Если считать, что все простейшие операции расчитываются процессором за примерно одинаковое время, то работа сигмоидальной функции активации после произведенного суммирования (которое займет одинаковое время) будет медленее пороговой функции активации как 1:4.
Функция оценки работы сети[]
В тех случаях, когда удается оценить работу сети обучение нейронных сетей можно представить как задачу оптимизации. Оценить — означает указать количественно хорошо или плохо сеть решает поставленные ей задачи. Для этого строится функция оценки. Она, как правило, явно зависит от выходных сигналов сети и неявно (через функционирование) — от всех ее параметров. Простейший и самый распространенный пример оценки — сумма квадратов расстояний от выходных сигналов сети до их требуемых значений: , где — требуемое значение выходного сигнала.


Метод наименьших квадратов далеко не всегда является лучшим выбором оценки. Тщательное конструирование функции оценки позволяет на порядок поысить эффективность обучения сети, а также получать дополнительную информацию — «уровень уверенности» сети в даваемом ответе[6].
Описание алгоритма[]
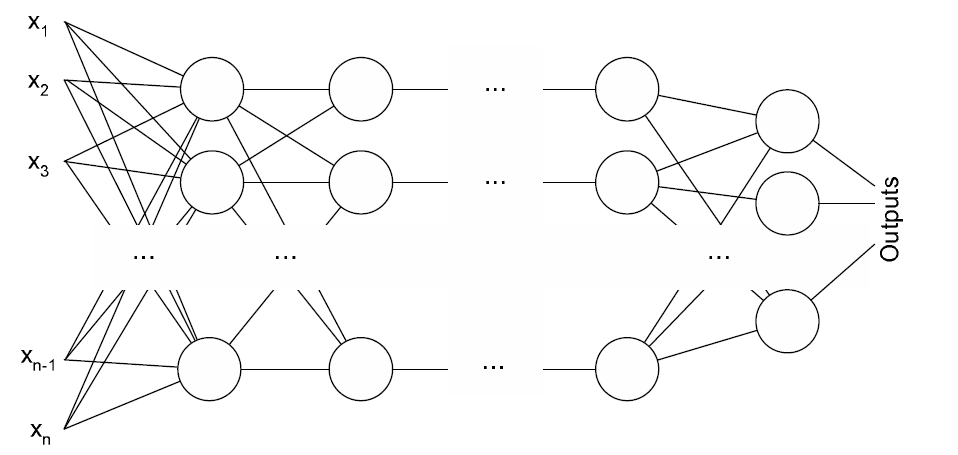
Архитектура многослойного перцептрона
Алгоритм обратного распространения ошибки применяется для многослойного перцептрона. У сети есть входы , выходы Outputs и внутренние узлы. Перенумеруем все узлы (включая входы и выходы) числами от 1 до N. Обозначим через вес, стоящий на ребре, соединяющем i-ый и j-ый узлы, а через — выход i-го узла. Если у нас m тестовых примеров с целевыми значениями выходов , , то функция ошибки, полученная по методу наименьших квадратов, выглядит так:






Как модифицировать веса? Мы будем реализовывать стохастический градиентный спуск, то есть будем подправлять веса после каждого тестового примера. Нам нужно двигаться в сторону, противоположную градиенту, то есть добавлять к каждому весу

где

Производная считается следующим образом. Пусть сначала , то есть интересующий нас вес входит в перцептрон последнего уровня. Сначала отметим, что влияет на выход перцептрона только как часть суммы , где сумма берется по входам j-го узла. Поэтому



Аналогично, влияет на общую ошибку только в рамках выхода j-го узла (напоминаем, что это выход всей сети). Поэтому



Если же j-й узел — не на последнем уровне, то у него есть выходы; обозначим их через Children(j). В этом случае
,

и
.

Ну а — это в точности аналогичная поправка, но вычисленная для узла следующего уровня (будем обозначать ее через — от она отличается отсутствием множителя . Поскольку мы научились вычислять поправку для узлов последнего уровня и выражать поправку для узла более низкого уровня через поправки более высокого, можно уже писать алгоритм. Именно из-за этой особенности вычисления поправок алгоритм называется алгоритмом обратного распространения ошибки (backpropagation). Краткое резюме проделанной работы:




- для узла последнего уровня

- для внутреннего узла сети

- для всех узлов

Получающийся алгоритм представлен ниже. На вход алгоритму, кроме указанных параметров, нужно также подавать в каком-нибудь формате структуру сети. На практике очень хорошие результаты показывают сети достаточно простой структуры, состоящие из двух уровней нейронов — скрытого уровня (hidden units) и нейронов-выходов (output units); каждый вход сети соединен со всеми скрытыми нейронами, а результат работы каждого скрытого нейрона подается на вход каждому из нейронов-выходов. В таком случае достаточно подавать на вход количество нейронов скрытого уровня.
Алгоритм[]
Алгоритм: BackPropagation

- Инициализировать маленькими случайными значениями.
- Повторить NUMBER_OF_STEPS раз:
- Для всех d от 1 до m:
- Подать на вход сети и подсчитать выходы каждого узла.
- Для всех
- .
- Для каждого уровня l, начиная с предпоследнего:
- Для каждого узла j уровня l вычислить
- .
- Для каждого ребра сети {i, j}
- .
- Выдать значения .







{kind=link}
Математическая интерпретация обучения нейронной сети[]
На каждой итерации алгоритма обратного распространения весовые коэффициенты нейронной сети модифицируются так, чтобы улучшить решение одного примера. Таким образом, в процессе обучения циклически решаются однокритериальные задачи оптимизации.
Обучение нейронной сети характеризуется четырьмя специфическими ограничениями, выделяющих обучение нейросетей из общих задач оптимизации: астрономическое число параметров, необходимость высокого параллелизма при обучении, многокритериальность решаемых задач, необходимость найти достаточно широкую область, в которой значения всех минимизируемых функций близки к минимальным. В остальном проблему обучения можно, как правило, сформулировать как задачу минимизации оценки. Осторожность предыдущей фразы («как правило») связана с тем, что на самом деле нам неизвестны и никогда не будут известны все возможные задачи для нейронных сетей, и, быть может, где-то в неизвестности есть задачи, которые несводимы к минимизации оценки. Минимизация оценки — сложная проблема: параметров астрономически много (для стандартных примеров, реализуемых на РС — от 100 до 1000000), адаптивный рельеф (график оценки как функции от подстраиваемых параметров) сложен, может содержать много локальных минимумов.
Недостатки алгоритма[]
Несмотря на многочисленные успешные применения обратного распространения, оно не является панацеей. Больше всего неприятностей приносит неопределенно долгий процесс обучения. В сложных задачах для обучения сети могут потребоваться дни или даже недели, она может и вообще не обучиться. Причиной может быть одна из описанных ниже.
Паралич сети[]
В процессе обучения сети значения весов могут в результате коррекции стать очень большими величинами. Это может привести к тому, что все или большинство нейронов будут функционировать при очень больших значениях OUT, в области, где производная сжимающей функции очень мала. Так как посылаемая обратно в процессе обучения ошибка пропорциональна этой производной, то процесс обучения может практически замереть. В теоретическом отношении эта проблема плохо изучена. Обычно этого избегают уменьшением размера шага η, но это увеличивает время обучения. Различные эвристики использовались для предохранения от паралича или для восстановления после него, но пока что они могут рассматриваться лишь как экспериментальные.
Локальные минимумы[]
Обратное распространение использует разновидность градиентного спуска, то есть осуществляет спуск вниз по поверхности ошибки, непрерывно подстраивая веса в направлении к минимуму. Поверхность ошибки сложной сети сильно изрезана и состоит из холмов, долин, складок и оврагов в пространстве высокой размерности. Сеть может попасть в локальный минимум (неглубокую долину), когда рядом имеется гораздо более глубокий минимум. В точке локального минимума все направления ведут вверх, и сеть неспособна из него выбраться. Статистические методы обучения могут помочь избежать этой ловушки, но они медленны.
Размер шага[]
Внимательный разбор доказательства сходимости[3] показывает, что коррекции весов предполагаются бесконечно малыми. Ясно, что это неосуществимо на практике, так как ведет к бесконечному времени обучения. Размер шага должен браться конечным, и в этом вопросе приходится опираться только на опыт. Если размер шага очень мал, то сходимость слишком медленная, если же очень велик, то может возникнуть паралич или постоянная неустойчивость. П. Д. Вассерман[7] описал адаптивный алгоритм выбора шага, автоматически корректирующий размер шага в процессе обучения. В книге А. Н. Горбаня[8] предложена разветвлённая технология оптимизации обучения.
См. также[]
Литература[]
- Уоссермен Ф. Нейрокомпьютерная техника: Теория и практика. — М.: «Мир», 1992.
- Хайкин С. Нейронные сети: Полный курс. Пер. с англ. Н. Н. Куссуль, А. Ю. Шелестова. 2-е изд., испр. — М.: Издательский дом Вильямс, 2008, 1103 с.
Внешние ссылки[]
- Копосов А.И., Щербаков И.Б., Кисленко Н.А., Кисленко О.П., Варивода Ю.В. и др. Отчет по научно-исследовательской работе "Создание аналитического обзора информационных источников по применению нейронных сетей для задач газовой технологии". — Москва: ВНИИГАЗ, 1995.
- Миркес Е. М., Нейроинформатика: Учеб. пособие для студентов с программами для выполнения лабораторных работ. Красноярск: ИПЦ КГТУ, 2002, 347 с. Рис. 58, табл. 59, библиогр. 379 наименований. ISBN 5-7636-0477-6
Примечания[]
- ↑ Werbos P. J., Beyond regression: New tools for prediction and analysis in the behavioral sciences. Ph.D. thesis, Harvard University, Cambridge, MA, 1974.
- ↑ Галушкин А. И. Синтез многослойных систем распознавания образов. — М.: «Энергия», 1974.
- ↑ 3,0 3,1 Rumelhart D.E., Hinton G.E., Williams R.J., Learning Internal Representations by Error Propagation. In: Parallel Distributed Processing, vol. 1, pp. 318—362. Cambridge, MA, MIT Press. 1986.
- ↑ Барцев С. И., Охонин В. А. Адаптивные сети обработки информации. Красноярск : Ин-т физики СО АН СССР, 1986. Препринт N 59Б. — 20 с.
- ↑ Барцев С. И., Гилев С. Е., Охонин В. А., Принцип двойственности в организации адаптивных сетей обработки информации, В кн.: Динамика химических и биологических систем. — Новосибирск: Наука, 1989. — С. 6-55.
- ↑ Миркес Е. М., — Новосибирск: Наука, Сибирская издательская фирма РАН, 1999. — 337 с. ISBN 5-02-031409-9 Другие копии онлайн: [1]
- ↑ Wasserman P. D. Experiments in translating Chinese characters using backpropagation. Proceedings of the Thirty-Third IEEE Computer Society International Conference.. — Washington: D. C.: Computer Society Press of the IEEE, 1988.
- ↑ Горбань А. Н. Обучение нейронных сетей.. — Москва: СП ПараГраф, 1990.
Эта страница использует содержимое раздела Википедии на русском языке. Оригинальная статья находится по адресу: Метод обратного распространения ошибки. Список первоначальных авторов статьи можно посмотреть в истории правок. Эта статья так же, как и статья, размещённая в Википедии, доступна на условиях CC-BY-SA .